Uncompressed WAV
320kbps mp3
192kbps mp3
128kbps mp3
Uncompressed WAV
64kbps mp3
48kbps mp3
32kbps mp3
8kbps mp3
Jewelry of text in today’s presentation is the unedited output of Apple speech recognition
God help us all
detecting speech is hard
Noise
Homophones
Vocabulary and limited training data
Variability in Speech
Speaker variability
Yoshihisa Ishikawa’s one-night stay at a robot-staffed hotel in western Japan wasn’t relaxing. He was roused every few hours during the night by the doll-shaped assistant in his room asking: “Sorry, I couldn’t catch that. Could you repeat your request?” By 6 am, he realized the problem: His heavy snoring was triggering the robot.
Speech tools are expected to work anywhere
Headphones
Traffic
MusicPlaying in the background
Many tools are used
A raise of multiple microphonesTo localize sound
Amplitude detectionTo identifyThe target speaker
Filtering to removeEchoes and background noise
Deep learning systems design to enhance speech
It’s easier to removeI Squealed in ago
Multiple close talkers present major problems
I am putting noise can always win
Common to many sound tasks
The crucial to making a working system
Two words which are spelled differently, with different meanings, and the same sounds
then/than
their/there/they’re
Will/we’ll
Genes/Jeans
Lift/Lyft
Outtie/Audi
Lie/Lye

Humans use meaning to disambiguate
He stole a walk from the Chinese restaurant
He live forever, it must be good genes
Use lie to make so
Without knowledge of the world, ASR systems can’t cheat
Probability models
Will get into these laterIn the quarter
QuoteWhat’s the probabilityOf this word, given the other oneQuote
🤦♂️
Domain specific knowledge
How likely is this person to talk about jeansVersus jeans
Medical versus versus legal vs. general purpose dictation
Some estimate the number of words80 speakers no between 25 and 30,000
Much larger in specific domains
Names and foreign borrowingsAdd additionalComplexity
Bill frequency Castrol coefficient
(
Dyshidrotic eczema
proof seven and presumption great hearing
Adenocarcinoma arising into pavilions at know
“The wallet that says badass motherfucker on it”
The Dalai Lama,Fidel Castro,Barack Obama,Zygmunt Fry Singer,Yelling at people can bitch,Gabriella Italian
“… again, this is Melinda Night, calling for a reference check for Eliza colonoscopy”
Siri did not understand ‘Eliza Kolmanovsky’
Packaging your product for specific domains
Mining existing data from the customer
IntegratingAddress book information for name recognition
Fuzzy searching usingA list of possibilities
Changes in tempo
Changes in volume
Changes in pitch
Changes in dialect
Changes in degree of articulation
Producing speech With an unusually Hi clarity and articulation
Producing speech with minimal effort And a minimally distinct gestures
if you trained only on conversational casual data you’re only effective there
if you train on people reading books aloud in a sound booth, that’s what you’ll be best at
you need to choose training data that reflects the task well

ASR needs to accommodateTo all states of your voice
You can’t learn to specificallyWhat you Soundlike
Differences in pitch
Differences in dialect
Differences inLanguage background
Differences in vocal track size and anatomy
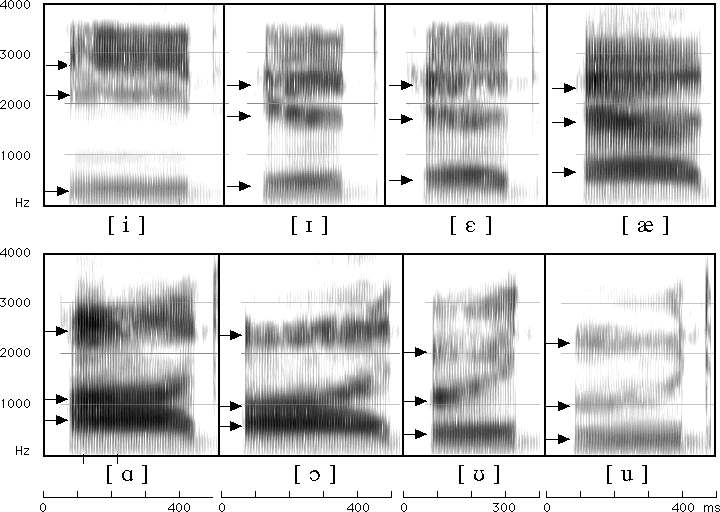
Different American English vowels, as spoken by a male speaker
They vary depending on the tongue’s position
Different formants from the same speaker mean different vowels
![]()
Even the same speaker will have variation from moment to moment
Sometimes we misarticulate, accidentally making the wrong vowel quality
Or we talk with food in our mouths, producing different resonances
Or sometimes, we’re just plain lazy
This leads to constant and massive changes in vowel production
![]()
![]()

We stack the deck in our favor in the grammar of the language
We use non-formant-related cues such as vowel length
We adjust to individual speakers (or vocal tracts) through Speaker Normalization
We attend to context
Context helps us to understand words even if the phonemes are acoustically ambiguous
Easier to understand “Hello” in its normal conversational context
If you’re not expecting a word, you’ll have to fight harder to understand it.
“Hi, John! Partial Nephrectomy!”
“Ohh, Invasive Adenocarcinoma arising in tubulovillious adenoma”
Nobody runs into rooms and shouts “bat!”
Sometimes it’s explicitParenthesisQuoteFirst, read this paragraph for meQuote parenthesis
Sometimes assumptions are made on the basis of the pitchAnd other than domestic factors
Sometimes it emerges from the data
![]()
English vowels different duration
Context can be very very helpful
The more you can predict what is being said,The better
Incredibly high pitches
Small vocal tracks
PoorSpeech abilitiesComparatively
Just bad communicators in general
Yet we expect a laxative work just fine
Every single user sounds different,But expect the same results
This is absolutely amazing,And terrifying
Speech recognition is really hard
There are many sources of noise, and ways to deal with it
Homophones cause amazingAnd terrible problems
Your system is only as good as its vocabulary
Speech is very variable within speakers
Speech varies across speakers as well