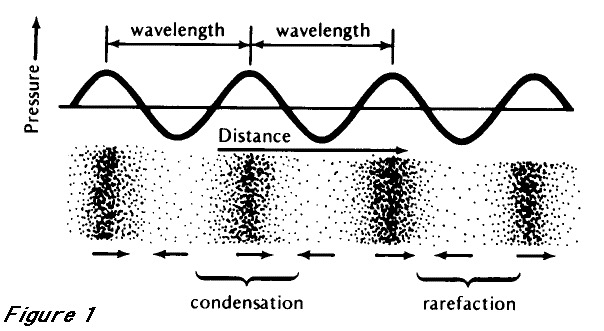
Capturing Pressure variations
Computer Audio, Sampling, and Quantization
Audio Codecs and Formats
Audio Compression
Noise Reduction
Using sound in machine learning
For most of our species history, this wasn’t a thing
How do we capture and recreate the pattern of sound pressure?


The stylus wears away the groove
The power of the air pressure limited the strength of the medium
‘The Lost Chord’ by Arthur Sullivan (1888)
You want a soft medium for capture
… and a hard medium for playback
Air pressure only provides so much power

Electrical signals are easy to amplify
… and easier to store
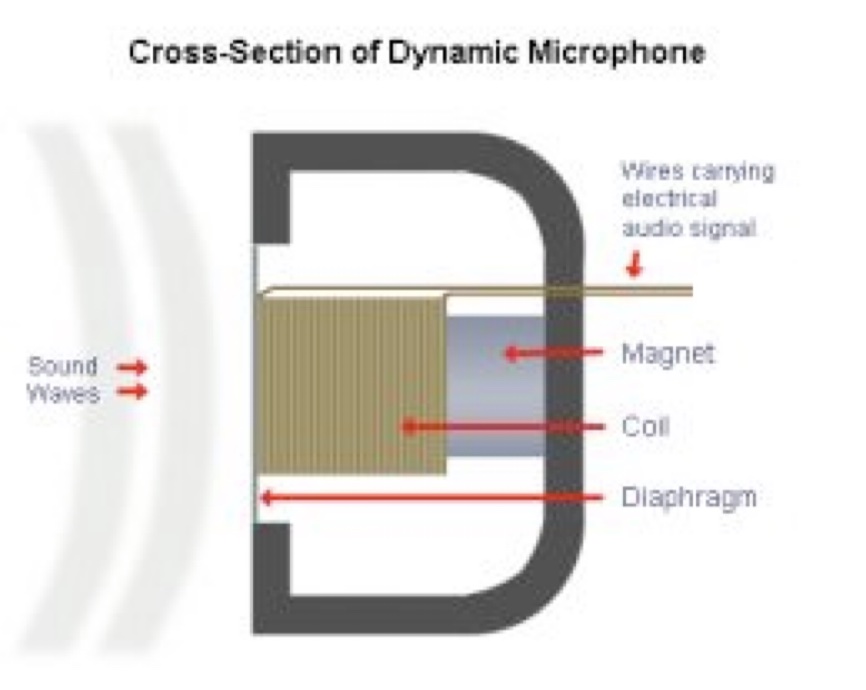
A Microphone transduces air pressure patterns into electrical patterns
‘Give me a pattern of voltage that matches the pattern of compression and rarefaction’
Air pressure pushes a membrane, moving a coil of wire around a magnet, inducing voltage
Durable, but less sensitive
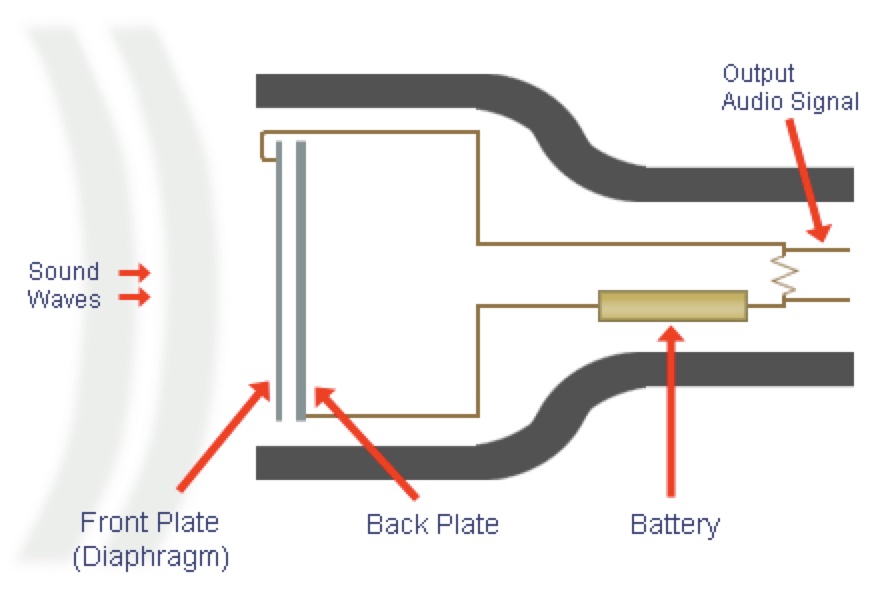
Air pressure pushes one plate closer to another, producing changes in capacitance
This can then be amplified using external (‘phantom’ or 48v) power for output
More sensitive, but more fragile too!
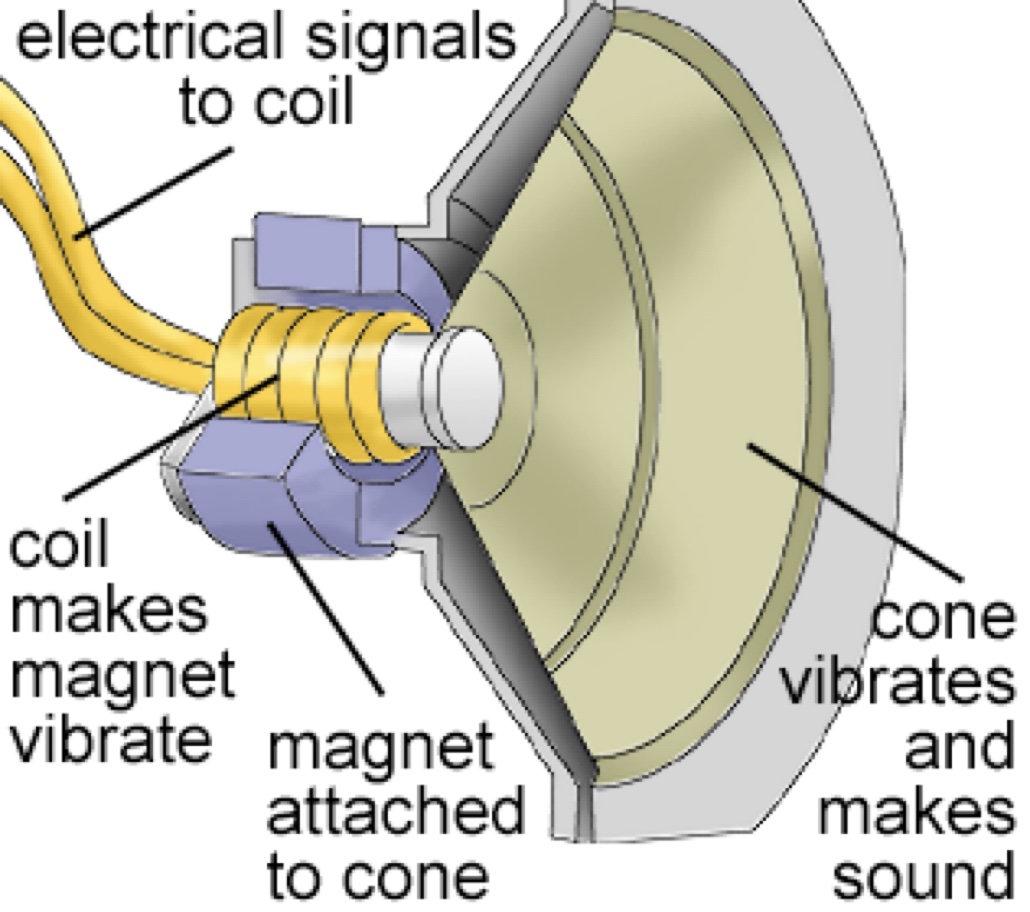
You can amplify it, transmit it, modify it and store it
You can even recreate the air pressure movements
Dynamic microphones in reverse
Changes in voltage move a membrane attached to a coil
This ‘kicks’ the air in the desired pattern of compression


010001110010101000100101101010101010
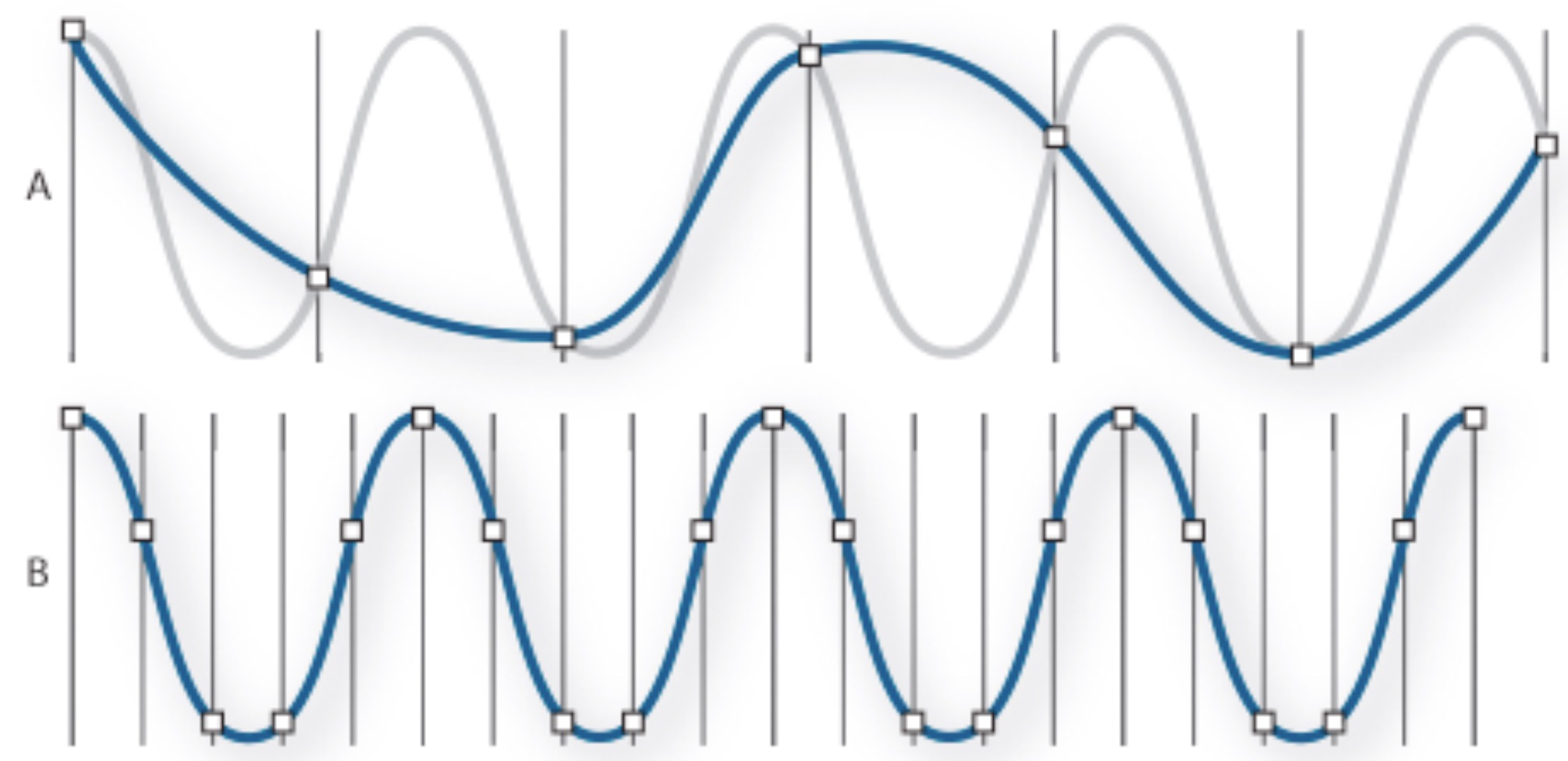
Also known as ‘digitization’, ‘discretization’, or ‘sampling’
“Let’s just measure the sound a LOT and store those values”
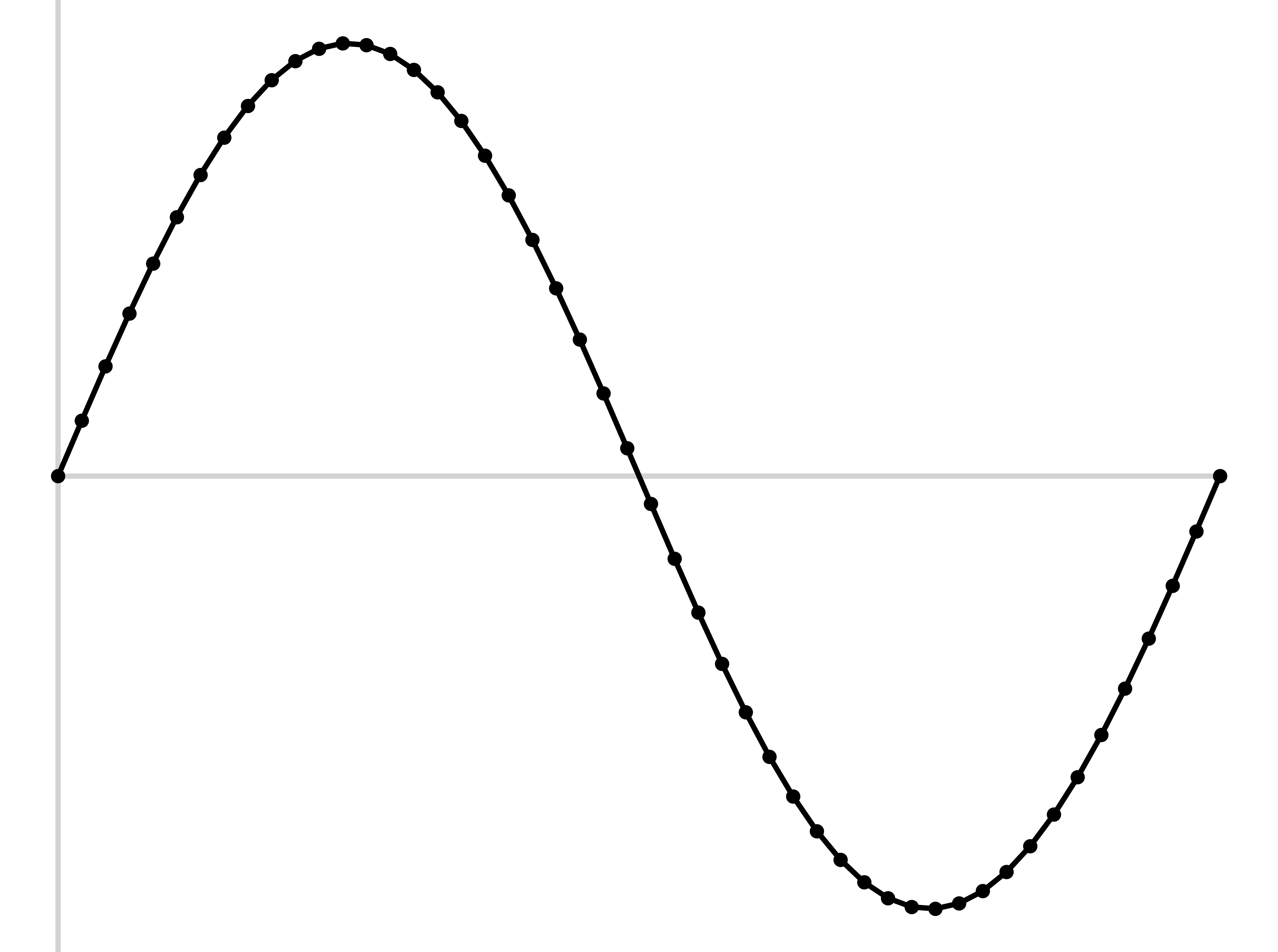
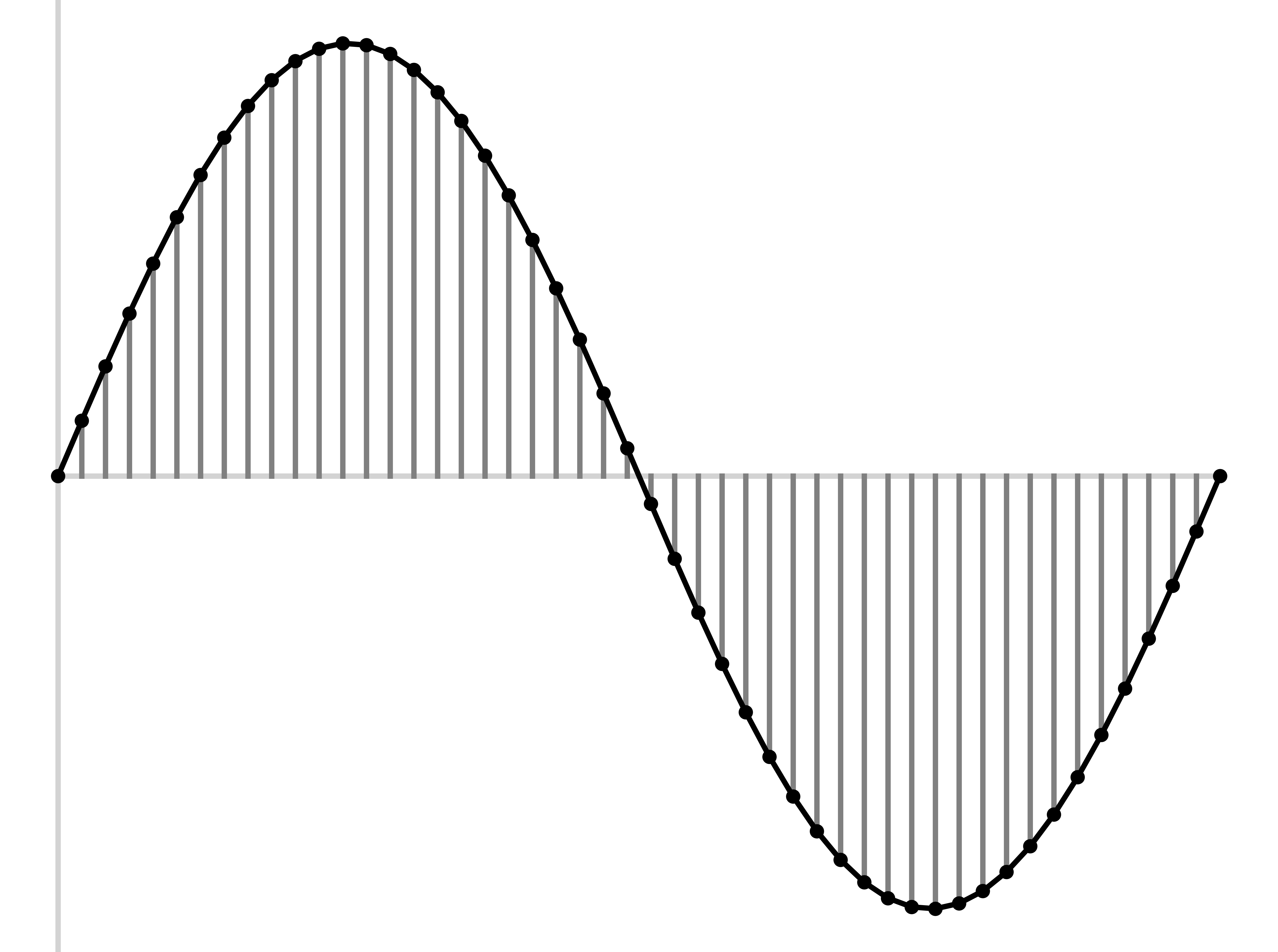
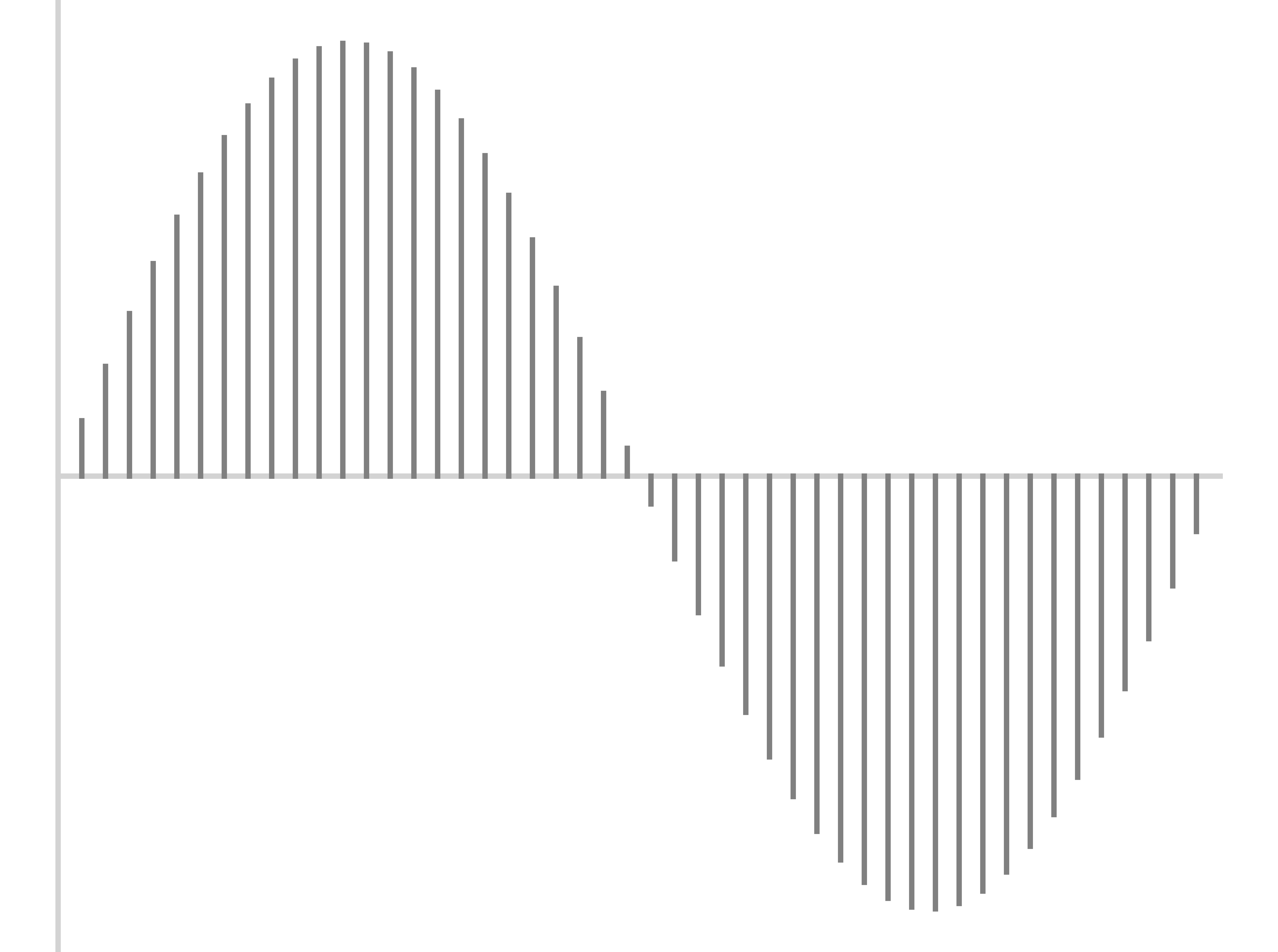
Sample the wave many times per second
Record the amplitude at each sample
The resulting wave will faithfully capture the signal
This is called the ‘Sampling Rate’
Measured in samples per second (Hz)
| ### Good sampling rates capture the necessary set of frequencies |
|

The highest frequency captured by a sample signal is one half the sampling rate
44,100 Hz
22,050 Hz
11,025 Hz
6000 Hz
44,100 Hz
6000 Hz
3000 Hz
1500 Hz
800 Hz
Radio was historically less than this
CDs are at 44,100 Hz
DVDs are at 48,000 Hz
High-End Audio DVDs are at 96,000 Hz
Some people want 192,000 Hz
This covers the range of human hearing entirely
You can go higher, but don’t go lower!
If your recording setup doesn’t have enough dynamic range, your waveforms will be cut off
This makes for awful analyses in the future
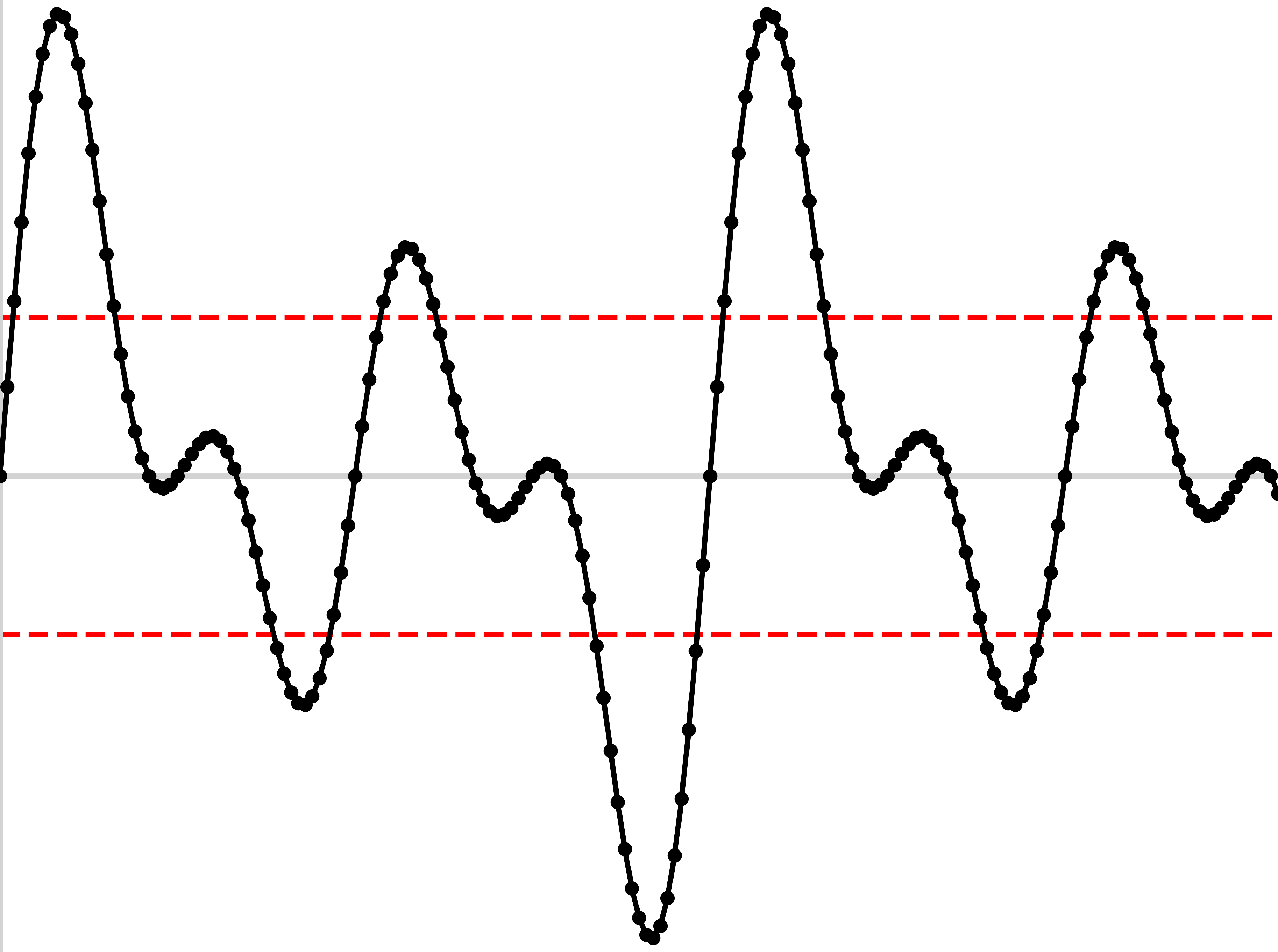
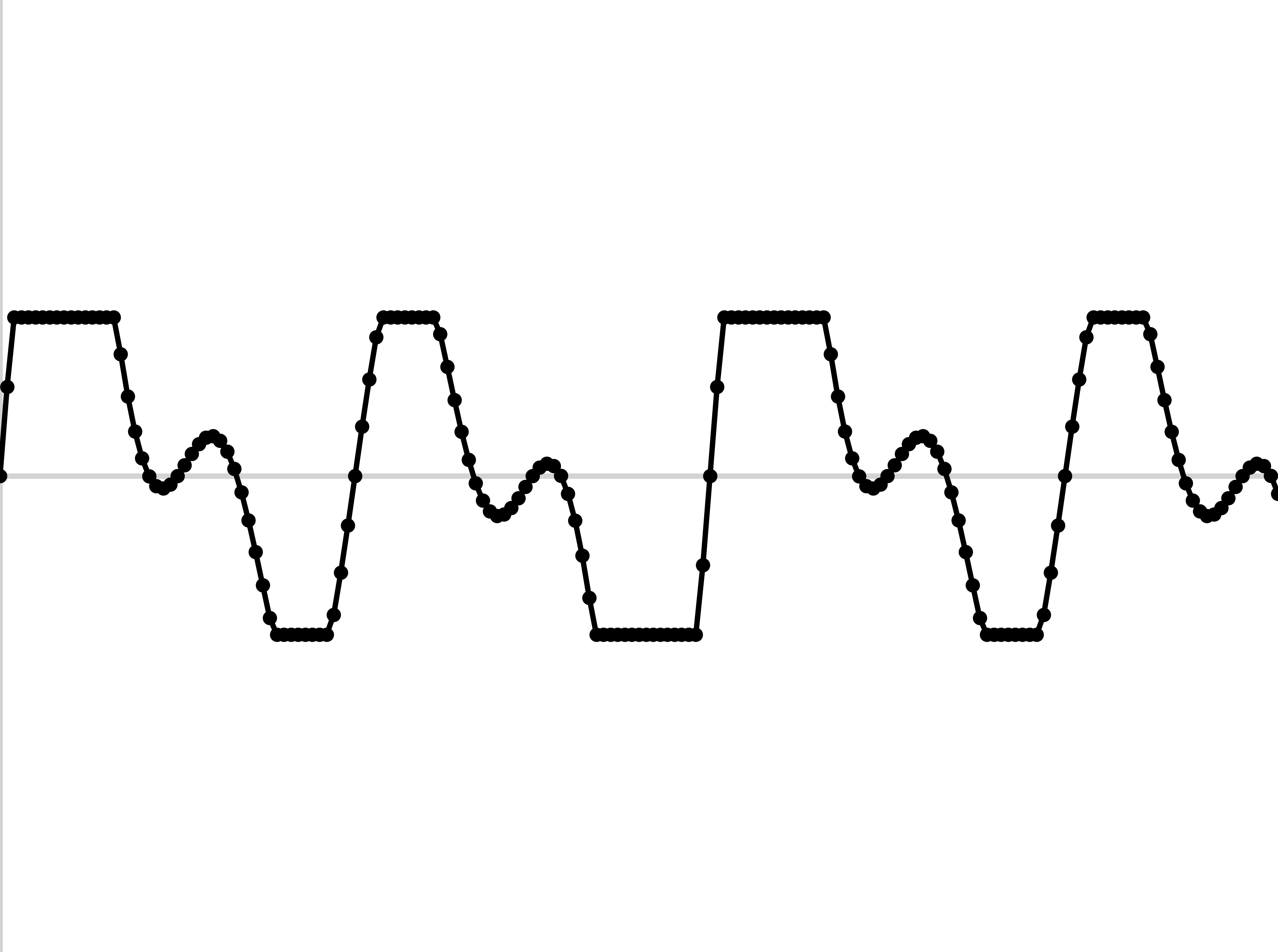
Make sure the loudest signals are captured without clipping
… but that the mid-range signals aren’t too quiet, either!
We want to store individual values for amplitude
We want to store values with enough precision to capture the wave well
… but more precision means more numbers (which need more space to store!)
We need to find the right bit depth
How many bits of amplitude information do we store for each sample?
4 bits gives 16 ‘levels’
16 bits gives 65,563 levels
24 bits gives 16,777,216 levels
Bit Depth != Bit Rate!
If it’s not spoken of, it’s 16 bit
There’s no reason to go higher, practically
Don’t go lower!
Any audible audio signal can be captured digitally, c.f. the nyquist theorem
We can capture greater bit depth than we can hear
‘More detail’ means ‘the noise and distortion I appreciate’
Audiophiles are generally slightly insane
“ADC” or “AD” chips go from analog signals to digital samples
“DAC” or “DA” chips reverse the process, and create analog signals from digital samples
Every digital device that uses sound needs both
Other components provide (e.g.) level control, mixing, phantom power, different inputs
They can vary massively in quality
WAV files are effectively large lists of amplitudes, with a sampling rate and channel info at the top
AIFF is the same idea, but Apple’s own format
You can freely and losslessly turn WAV into AIFF and vice versa
You should be a bit scared of any device which won’t give you WAV or AIFF or FLAC
Disk space is ridiculously cheap
Not all software supports all filetypes
Format rot is a thing!
You’re trying to store a bunch of sounds in a limited space
You’re trying to save bandwidth costs when sending sound or music
You need to allow people with slow internet to talk synchronously by voice
You want to encrypt the signal so that others can’t hear it without a key
You want to send something smaller than large lists of samples!
(This is a portmanteau of encoder-decoder)
In the audio world, it encodes the sample amplitudes into a different and more space-efficient format
Audio file formats are packages including data in one or more codecs
All videos include audio which is stored or compressed with a codec
It’s possible to have different codecs with the same ‘file type’
Generally this distinction isn’t important to linguists!
‘Uncompressed’ formats
‘Lossless’ compressed codecs
‘Lossy’ compressed codecs
‘Lossless’ files contain the data to reconstruct exactly what was captured by the ADC
There are other lossless formats like FLAC, WavPack, and Apple Lossless
These save space by cleverly saving the full data stream
e.g. “4000 samples of silence here” rather than 4,000 instances of “0.000000”
Lossless compression asks “What can I do to make these files smaller while still keeping all the data?”
Lossless compression is not a problem, and you can convert between formats


Lossless compression asks “What can I do to make the file smaller while keeping the same exact data?”
Lossy compression asks “What can I throw away to make the file smaller while keeping the human from noticing?”
Lossy compression is tuned to human perception!
mp3 is the most well known lossy codec
Your cell phone uses EVS, EVRC, AMR, or GSM
This one of the reasons old phones need to be changed
It’s also why hold music sounds like garbage
Zoom uses the Opus codec
Using things like Discrete Cosine Transform and LPC
Also uses psychoacoustic knowledge
“Let’s throw away or simplify the stuff that doesn’t matter as much to the human!”







The Bitrate dictates how many bits are required to capture a second of audio
‘Variable Bitrate’ (VBR) is the same idea, but adapts well to varied complexity
Lower bitrate means more compression, but more data loss
This is independent of bit depth!
Uncompressed WAV
320kbps mp3
192kbps mp3
128kbps mp3
Uncompressed WAV
64kbps mp3
48kbps mp3
32kbps mp3
8kbps mp3
Original from https://www.youtube.com/watch?v=wBnevSbdb7g
Compression is irreversible
Loss that you can’t hear can still affect measurements
Lower bitrates will have stronger effects, but just don’t
Some codecs purposefully use and remove linguistic data
These codecs were tuned for a data type and language
Opus is meant for speech and makes decisions based on contributors’ languages
Saving or collecting your data with compression changes it irrecoverably!
There is no harm in putting a bunch of WAV files into a zip file
Don’t worry if your backup service talks about compression
If the file extension at the end doesn’t change, you don’t care
Non-speech noise
Room echo and feedback
Typing and mouse clicks
Background clatter
Zoom (et al) want to send your voice, not the noise!
Discord, Zoom, Skype, and phones use speech tuned ‘noise reduction’ methods
Can be as simple as multiple mics allowing subtraction of background noise
These are increasingly neural-network-based filters
‘Noise Reduction’ algorithms are usually trained on language data
They can adversely affect classes of phones found in languages outside of the training data
“That sound isn’t found in the language I learned about, so it’s noise!”
Zoom doesn’t care for ejectives!
Sampling sound is necessary to put it into computers
16-bit bit depth and 44,100 Hz Sampling rate is a good idea
Record and save your data losslessly, ideally as .wav files
Lossy, compressed audio will negatively affect quality and measurement
Always record locally, losslessly, if doing remote fieldwork
No.
Do not.
Abso-[infix]-lutely not.
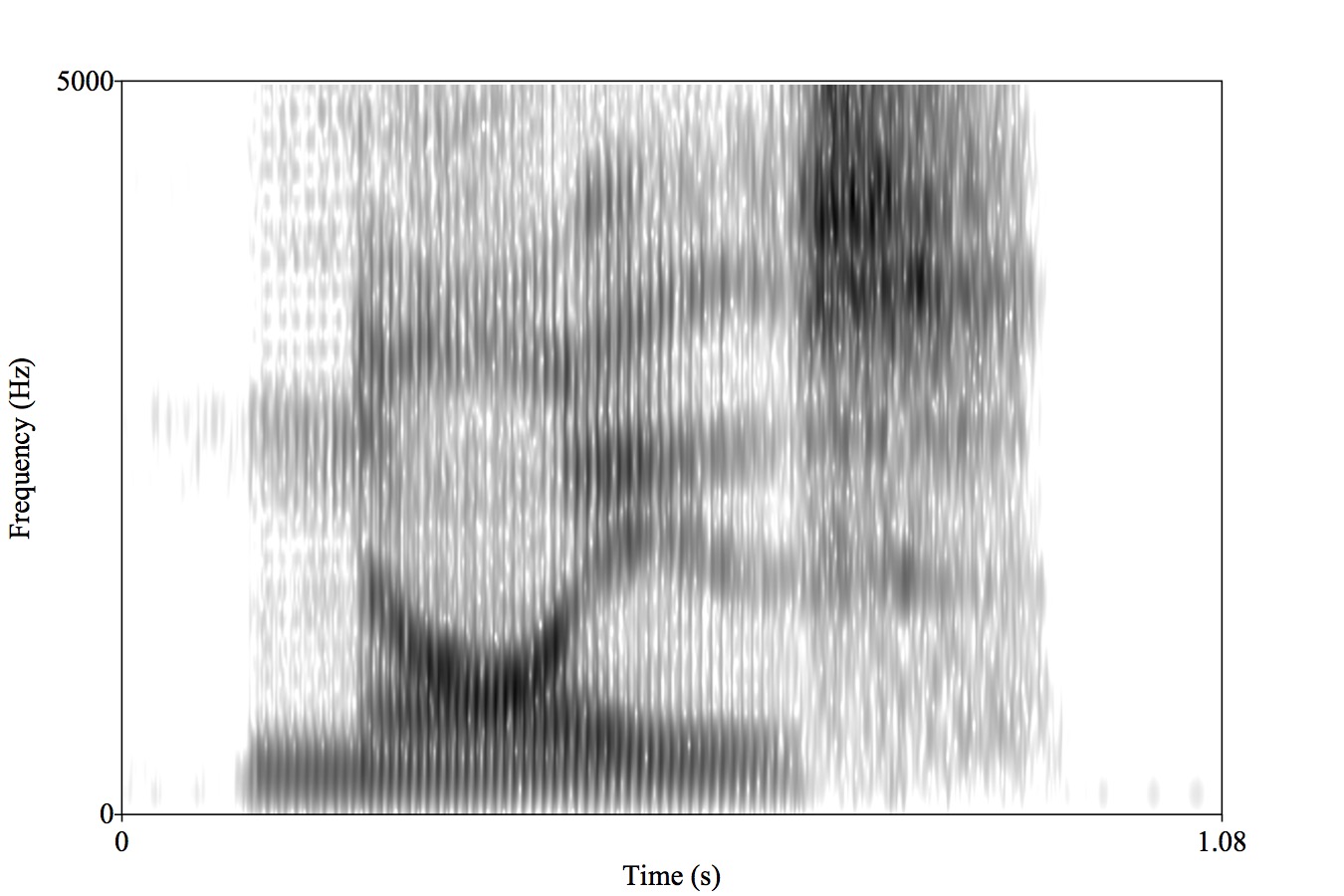
We’re going to use Neural Networks
… but what are the algorithms looking at?
It’s cheap and easy
NNs weren’t amazing at estimating frequency-based effects
Important parts of the signal live only in frequency band info
We want to be able to give it all the information we can, in the most useful format!
They reflect speech-specific understanding
They reflect articulatory facts
They’re efficient
They’re very transparent
Slow to extract
Require specialized algorithms to extract
They treat speech as “special”
We’re plugging it into a black box
We’re happy to plug in hundreds of features, if need be
We’d just as soon turn that sound into a boring matrix
This is a lot of signal processing
We’re going to teach the idea, not the practice
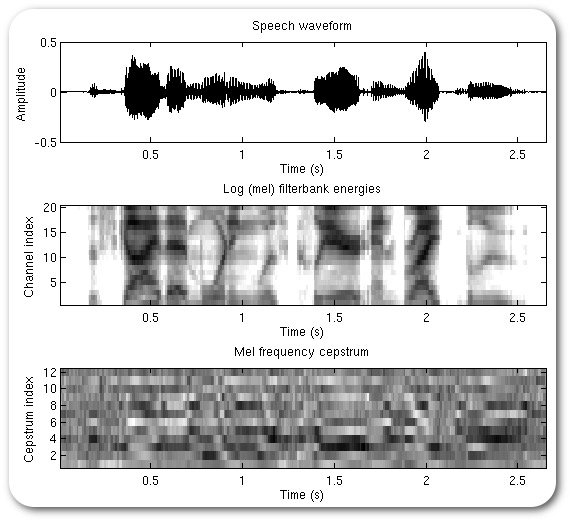
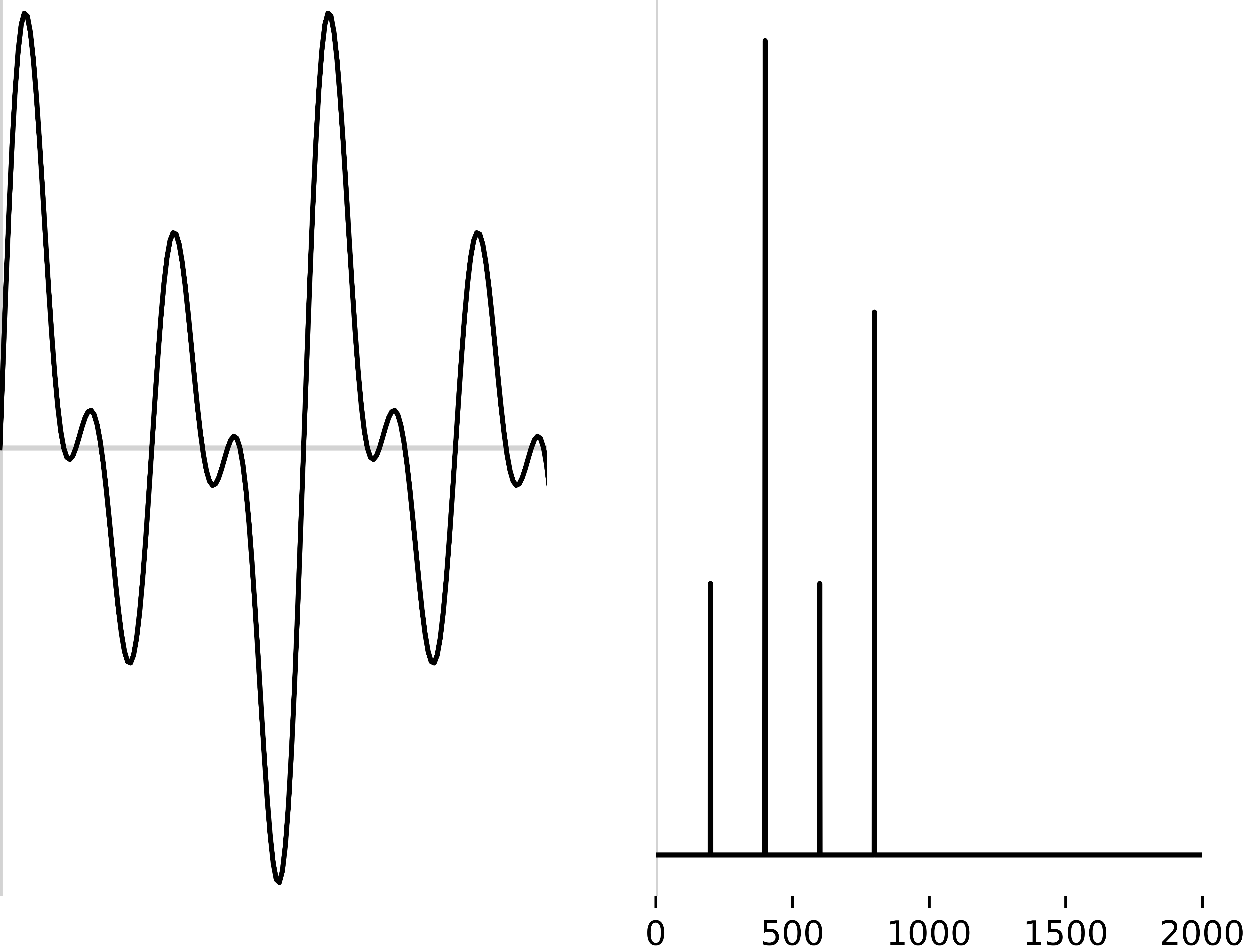
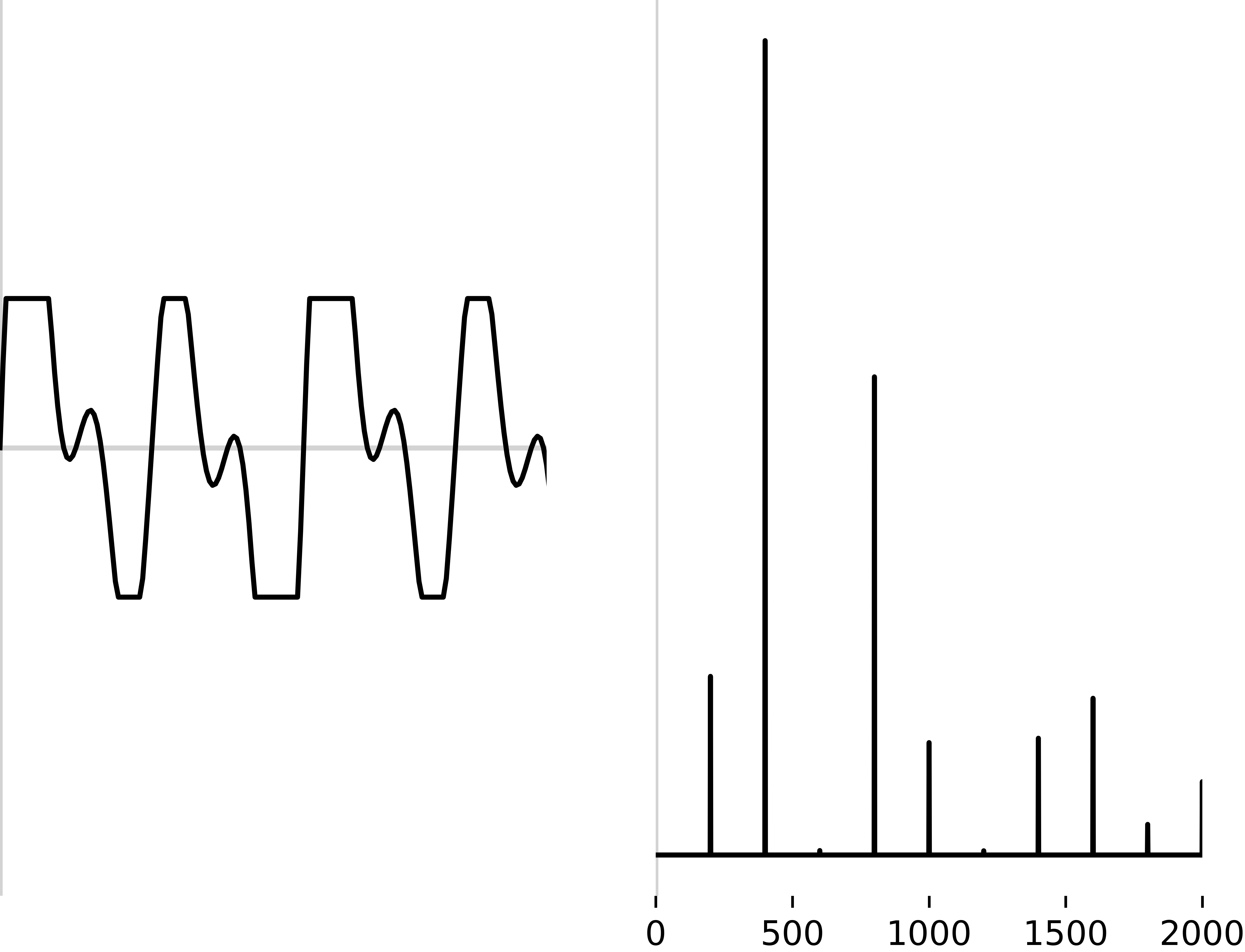
1: Create a spectrogram
2: Extract the most useful bands for speech (in Mels)
3: Look at the frequencies of this banded signal (repeating the Fourier Transform process)
4: Simplify this into a smaller number of coefficients using DCT
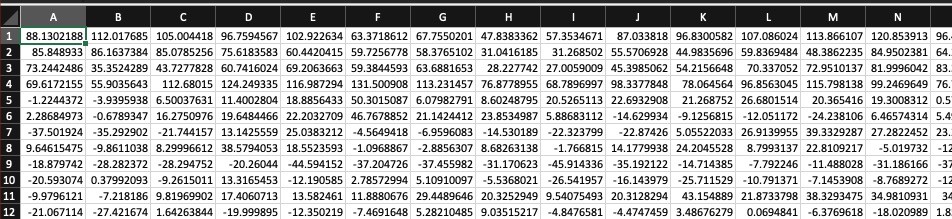
Many rows (representing time during the signal)
N columns (usually 13) with coefficients which tell us the spectral shape
It’s black-boxy, but we don’t care.
We’ve created a Matrix

Now let’s try computer audio on our own!